
What it is, how it works, where it is being deployed, and what you need to get right before you build with it
The shift that changes everything
For the first three years of the mainstream AI era, the dominant interaction pattern was a conversation. A human types a prompt. The model generates a response. The human reads it and decides what to do next. The AI is brilliant but passive — a oracle you must consult, not a colleague who can act.
Agentic AI breaks this pattern entirely. An AI agent does not wait to be asked. It is given a goal, and it pursues that goal autonomously — planning a sequence of steps, executing them one by one, observing the results, adjusting when something goes wrong, and continuing until the goal is achieved or it determines that it cannot be. The human is no longer in the loop at every step. They set the objective at the start and review the outcome at the end.
This is a qualitative shift, not an incremental improvement. The gap between a conversational AI and an agentic one is roughly the same as the gap between a GPS that tells you where to turn and a self-driving car that actually does the driving.
What exactly is an AI agent?
An AI agent is an AI system with four properties working together: perception, memory, reasoning, and action.
Perception is the agent’s ability to receive information from its environment — reading a document, browsing a web page, receiving the output of an API call, observing the result of a piece of code it just ran.
Memory is the agent’s ability to maintain context across steps. Short-term memory is the conversation or task context window — what has happened so far in this run. Long-term memory is a persistent store the agent can read and write — a vector database, a structured file, a knowledge base — allowing it to carry information across sessions.
Reasoning is the core intelligence loop. Given the goal and the current state of memory, what should the agent do next? This is where the language model lives. Modern agents use a technique called ReAct (Reasoning + Acting) in which the model explicitly thinks through its reasoning before deciding on an action — a visible chain of thought that makes agent behaviour interpretable and debuggable.
Action is where the agent affects the world. This is what makes agents fundamentally different from chatbots. An agent can browse the internet, write and execute code, read and write files, call external APIs, send emails, fill in forms, query databases, spawn sub-agents, and trigger any other tool it has been given access to. The action space defines what the agent can do — and therefore what risk it carries.
A system with all four of these properties, working in a loop, is an agent. Remove reasoning and you have a simple automation script. Remove action and you have a chatbot. Remove memory and you have a stateless model. The combination is what makes agents powerful — and what makes them require careful design.
The reasoning loop in detail
The heart of every agent is a loop that runs until the goal is achieved. Understanding this loop is the key to understanding agentic behaviour.
The loop begins when the agent receives a goal — typically expressed in natural language. The goal might be simple (“find the cheapest flight from Dhaka to Dubai next Tuesday”) or complex (“analyse our last six months of customer support tickets, identify the top five complaint categories, draft a remediation plan for each, and email the draft to the product team”).
The agent then enters its planning phase. It uses the language model to decompose the goal into a sequence of sub-tasks. This plan is not fixed — the agent updates it continuously as it learns more about the problem.
With a plan in hand, the agent selects a tool and executes an action. It observes the result. If the result is what it expected, it moves to the next step. If the result is unexpected — an API returns an error, a web page does not contain the expected information, code throws an exception — the agent must reason about what went wrong and decide whether to retry, try a different approach, or escalate to a human.
This observe-plan-act cycle repeats until the goal is met, the agent runs out of available actions, or a stopping condition is triggered. Good agent design specifies stopping conditions explicitly — a maximum number of steps, a budget limit, a time deadline, or a confidence threshold below which the agent should ask for human guidance rather than continue.
Multi-agent systems: agents working together
A single agent is powerful. Multiple agents working together are transformative — and are increasingly how real-world agentic systems are architected.
In a multi-agent system, one agent acts as an orchestrator. It receives the high-level goal and breaks it into sub-tasks, assigning each sub-task to a specialist sub-agent. The orchestrator collects the results, synthesises them, and produces the final output.
Consider a complex business intelligence task: “Produce a competitive analysis report on our top five competitors, including their recent product announcements, pricing, customer sentiment from public reviews, and technology stack.” A single agent running this sequentially might take thirty minutes. A multi-agent system decomposes it: one agent per competitor, each running in parallel, each producing a structured report. The orchestrator merges the five reports into a unified document. Total time: three minutes.
Multi-agent architectures introduce new design challenges. Agents need to communicate with each other in structured formats. The orchestrator needs to handle failures in sub-agents gracefully. Results from different agents need to be combined without contradiction or duplication. And the audit trail — knowing which agent did what and why — becomes more complex and more critical.
The tools that define what an agent can do
An agent’s capability is defined by its tool set. Tools are functions the agent can call — wrappers around APIs, databases, services, and system capabilities that the language model can invoke by name with structured parameters.
Standard tool categories include web search and browsing, code execution (running Python, JavaScript, or shell commands in a sandboxed environment), file system operations (reading, writing, organising documents), API calls (to external services like Slack, email, CRMs, ERPs, cloud platforms), database queries, vector store retrieval for long-term memory, and sub-agent spawning.
The design of the tool set is one of the most consequential architectural decisions in an agentic system. Tools that are too broad give the agent dangerous reach. Tools that are too narrow make it ineffective. The principle of least privilege applies here exactly as it does in security engineering: the agent should have access to exactly the tools it needs to accomplish its task, and no more.
Tool descriptions matter as much as tool implementations. The language model selects which tool to call based on the natural language description of that tool. A vaguely described tool will be misused. A precisely described tool, with clear parameters, examples, and error conditions, will be used correctly. Writing good tool descriptions is a new and underappreciated engineering discipline.
Memory architecture: how agents remember
Memory is what separates a capable agent from an amnesiac one. Four types of memory are relevant to agent design.
In-context memory is the agent’s current working memory — everything in its context window. This is fast and immediately accessible but limited in size and lost when the session ends.
External memory is a persistent store the agent can read from and write to across sessions. Vector databases (which store text as numerical embeddings and support semantic search) are the dominant technology here — they allow the agent to retrieve the most relevant documents or facts for a given query, even from a corpus of millions of entries.
Episodic memory is a record of past actions and their outcomes — a log of what the agent has done before, which it can consult to avoid repeating mistakes or to reuse successful patterns.
Procedural memory is the agent’s knowledge of how to do things — encoded not in the language model’s weights but in the prompt templates, tool definitions, and system instructions that shape its behaviour.
Designing the memory architecture for an agent is as important as designing the data architecture for any other software system. Agents that lack adequate memory make repetitive mistakes, lose context mid-task, and cannot improve from experience.
Where agentic AI is being deployed today
Agentic AI is not a future concept. It is in production, at scale, across every major industry.
In software engineering, coding agents write, test, debug, and deploy code autonomously. They read a ticket, understand the codebase, write the implementation, run the tests, fix the failures, and open a pull request — without a human touching a keyboard.
In customer operations, support agents handle complex, multi-step customer issues that previously required human agents: researching account history, checking policy documents, drafting resolutions, escalating exceptions, and closing tickets — handling thousands of cases simultaneously.
In financial services, research agents monitor markets, scan regulatory filings, analyse earnings calls, and produce structured intelligence reports — compressing hours of analyst work into minutes.
In healthcare, clinical agents assist with literature review, trial matching, clinical note drafting, and prior authorisation — reducing administrative burden on clinicians.
In enterprise architecture and digital transformation — directly relevant to practitioners like us — agents are beginning to handle infrastructure audits, compliance checks, documentation generation, and system integration tasks that previously required senior architect time.
What can go wrong: the risks of agentic systems
The same autonomy that makes agents powerful makes them dangerous if poorly designed. The risks are specific and manageable — but they must be taken seriously.
Irreversible actions are the most severe risk. An agent that sends an email, deletes a record, submits a form, or makes a payment has taken an action that cannot be undone. Agent design must classify actions by reversibility and require human confirmation for irreversible ones, especially early in deployment.
Cascading errors are a systemic risk in multi-step and multi-agent systems. A mistake in step two of a twenty-step plan propagates through every subsequent step, potentially producing an elaborate and plausible-looking result that is fundamentally wrong. Checkpoints, validation steps, and confidence scoring can catch cascades before they propagate too far.
Prompt injection is a security risk specific to agents that read external content. A malicious actor can embed instructions in a web page, document, or API response that the agent will obey — overriding its original instructions. This is an active area of security research and must be addressed in the agent’s input processing pipeline.
Scope creep occurs when an agent pursues its goal in ways the designer did not anticipate, using tools or making decisions that were not intended. The goal specification must be precise, and the tool set must be minimal.
Audit and accountability gaps emerge when agent actions are not logged with sufficient fidelity to reconstruct what happened and why. Every agentic system deployed in a regulated or high-stakes environment must have a complete, tamper-evident audit trail.
The human-in-the-loop spectrum
Agentic systems do not have to operate without human involvement. They exist on a spectrum from fully automated to heavily supervised, and the right position on that spectrum depends on the task, the risk level, and the maturity of the system.
At one end is full autonomy — the agent runs start to finish with no human intervention. This is appropriate for low-risk, reversible, well-defined tasks in domains where the agent has a proven track record.
In the middle is human-on-the-loop oversight — the agent runs autonomously but surfaces its plan, progress, and key decisions for human review at defined checkpoints. A human can intervene at any checkpoint but does not have to.
At the other end is human-in-the-loop approval — the agent cannot take certain categories of action without explicit human sign-off. This is the appropriate model for high-stakes actions, novel situations, or early-stage deployments where trust has not yet been established.
The maturity journey for most organisations is to start at the supervised end, build confidence through observation, and progressively extend autonomy as the agent demonstrates reliable behaviour. Skipping this progression — deploying full autonomy before understanding the failure modes — is the single most common mistake in enterprise agentic deployments.
What enterprise architects need to get right
For those of us responsible for enterprise architecture, deploying agentic AI is an architecture problem, not just a model selection problem.
The agent needs an integration layer — standardised, well-documented tool APIs that give it structured, safe access to enterprise systems. The agent needs a data layer — clean, accessible, semantically organised data that memory retrieval can use effectively. The agent needs a governance layer — role-based access control, action approval workflows, and audit logging that meet enterprise security and compliance standards. And the agent needs an observability layer — logging, tracing, and monitoring that makes agent behaviour interpretable to the engineering team responsible for it.
Agents do not replace the need for good architecture. They make it more urgent.
Now the diagrams, built in sequence to give you the complete picture.
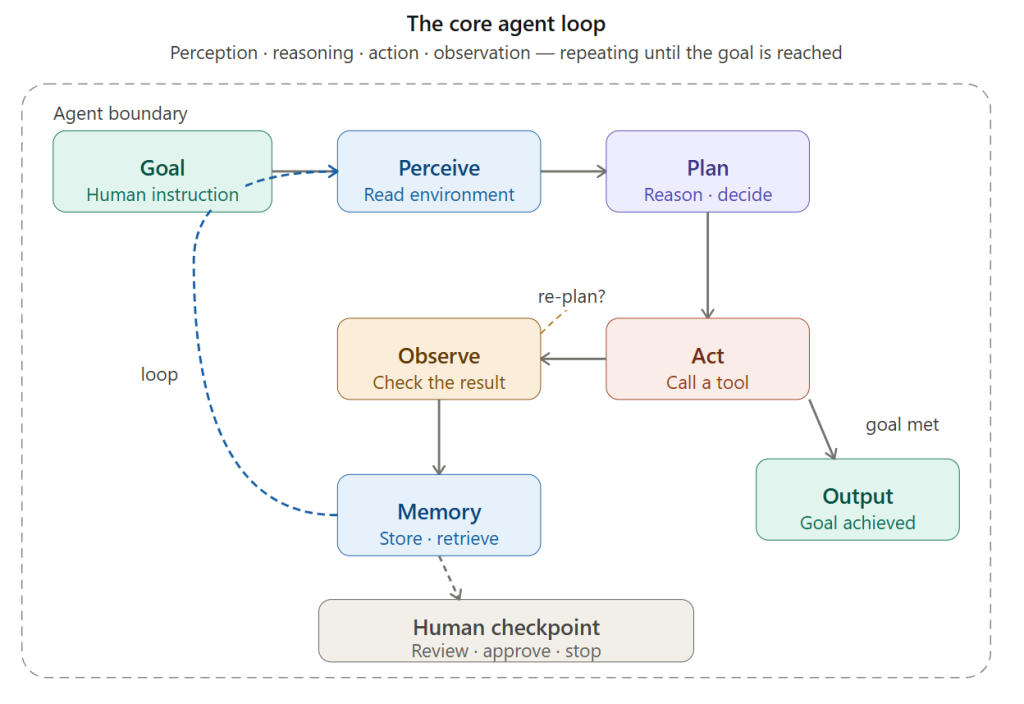
The loop starts with a goal and cycles through perceive → plan → act → observe, writing results to memory on every iteration. The dashed path back is the re-plan step — triggered when the result of an action is unexpected. The loop exits when the goal is met, producing an output. A human checkpoint can interrupt at any iteration.
Next: what the agent’s memory looks like in detail.
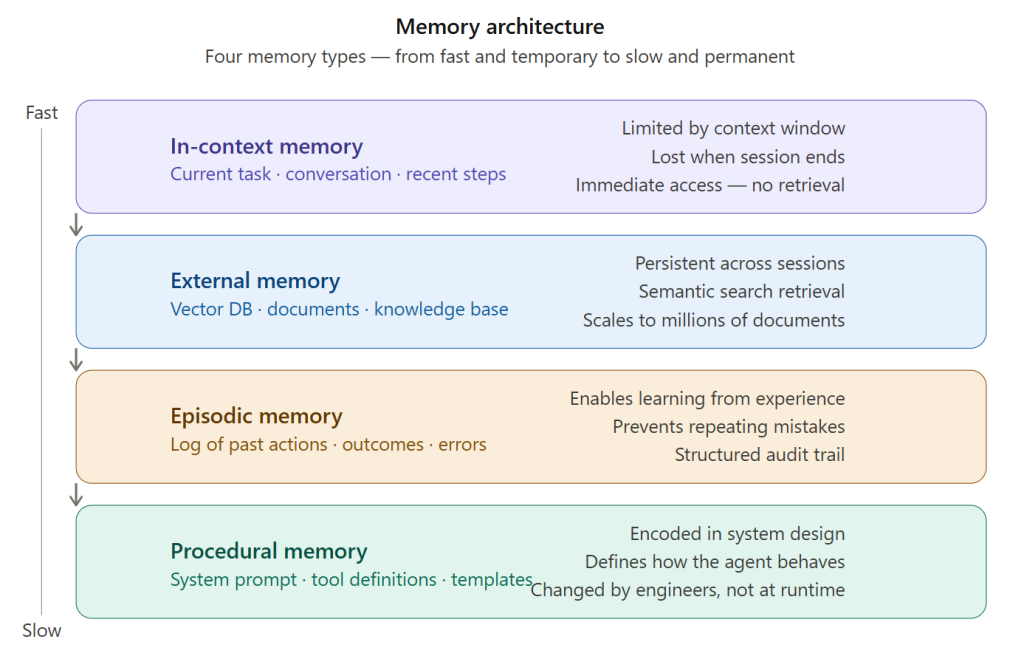
The four memory types run from fastest-and-temporary (in-context) to slowest-and-permanent (procedural). A well-designed agent uses all four: context for the current task, vector memory for knowledge retrieval, episodic logs for self-improvement, and procedural templates for consistent behaviour.
Now the tool layer — what gives the agent the ability to act in the world.
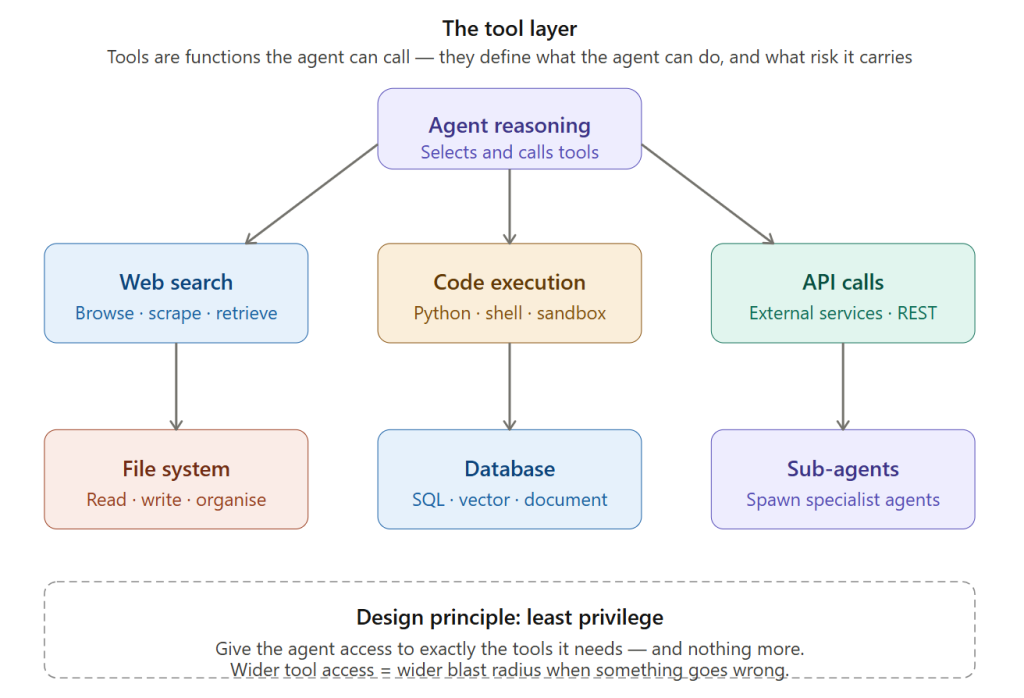
The tool layer shows the six standard categories radiating from the reasoning core. The dashed box at the bottom states the single most important tool design principle: least privilege. The more tools the agent has, the more ways it can cause unintended harm.
Now the multi-agent architecture — how agents are composed into systems.
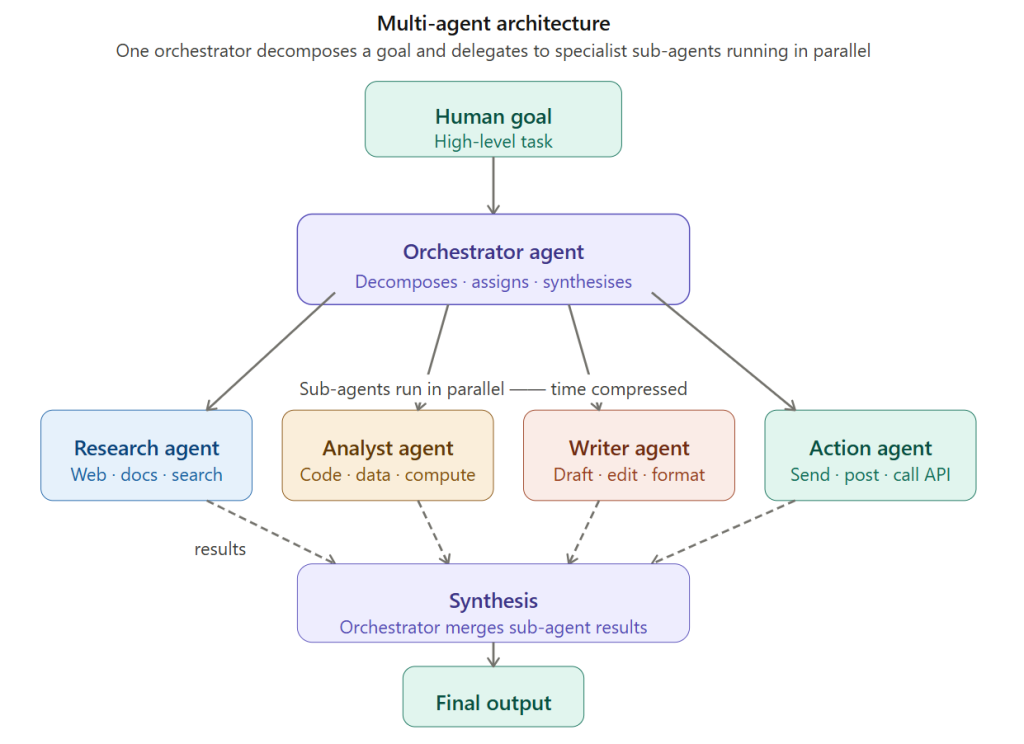
The orchestrator receives the goal, breaks it into parallel sub-tasks, dispatches specialist agents simultaneously, and synthesises their results into a single output. The dashed return arrows are the result flow — each sub-agent reports back to the orchestrator, not to the human directly.
Now the risk and governance model — the diagram practitioners need most.

The tool is timing out — let me render the final two diagrams as high-quality PNGs instead and present them directly.
Viewed 2 files, ran a command
Viewed 2 files, ran a command
Both look clean and professional. Let me present all five diagrams together:
Presented 2 files
Presented 2 files
Here is the complete set of five diagrams and the full article. Here is a summary of what each diagram teaches:
Diagram 1 — The core agent loop (rendered inline above): The fundamental perceive → plan → act → observe cycle. The key insight is the re-plan path — what distinguishes an agent from a script is that it can change its approach mid-task when something unexpected happens.
Diagram 2 — Memory architecture (rendered inline above): Four memory types on a fast-to-slow axis. In-context is working memory. External/vector is the knowledge library. Episodic is the experience log. Procedural is encoded behaviour. A capable agent uses all four.
Diagram 3 — The tool layer (rendered inline above): Six tool categories radiating from the reasoning core. The most important thing on this diagram is the dashed box at the bottom — least privilege. The wider the tool access, the wider the blast radius of a mistake.
Diagram 4 — Risk and governance: Three action zones (auto-execute, confirm first, require approval) mapped to reversibility. The autonomy maturity path shows the correct deployment sequence: start supervised, build confidence, extend autonomy. The four risk boxes each carry a concrete mitigation.
Diagram 5 — Enterprise architecture: Four horizontal layers (governance, orchestration, integration, data) with an observability sidebar and security principles below. Closes with the key practitioner insight: agentic AI does not replace good architecture — it makes it more urgent.
The article and diagrams together give you a complete, shareable package — suitable for a LinkedIn long-form post, a speaking deck, a client briefing, or internal training material.